Image Quilting, Text Quilting, Audio Quilting, City Quilting
Computer Graphics is one of my many interests, and so often when scrolling my feeds I will find interesting techniques or developments that I had never heard of before. Sometimes these techniques are decades old, but they are new to me, and the implications make my mind race, even though my own background isn't deeply technical. Some of my favorites include Recursive Wang Tiles for Real Time Blue Noise (An older method which allows for consistent infinitely zoomable stippling), Surface Stable Fractal Dithering (A newer method for consistent infinitely zoomable stippling specifically for 3D use cases), and an analysis of Mean Shift Clustering (A way to posterize or otherwise limit the amount of colors in an image, specifically helpful when using images with small amounts of colors like in this Minecraft Example)
The specific technique that caught my attention recently was Image Quilting. Image quilting is a way to take a given set of image tiles and cut them such that the boundaries between one tile and the next are less obvious. In the original video's case, this is used for infinite tiling of image textures without obvious repetition. But my mind went to using this same core logic for quilting together different images or even exploring non-image applications. I’ll quickly walk through the concept of image quilting for those of you who may not have seen the original explanation. In the below image:
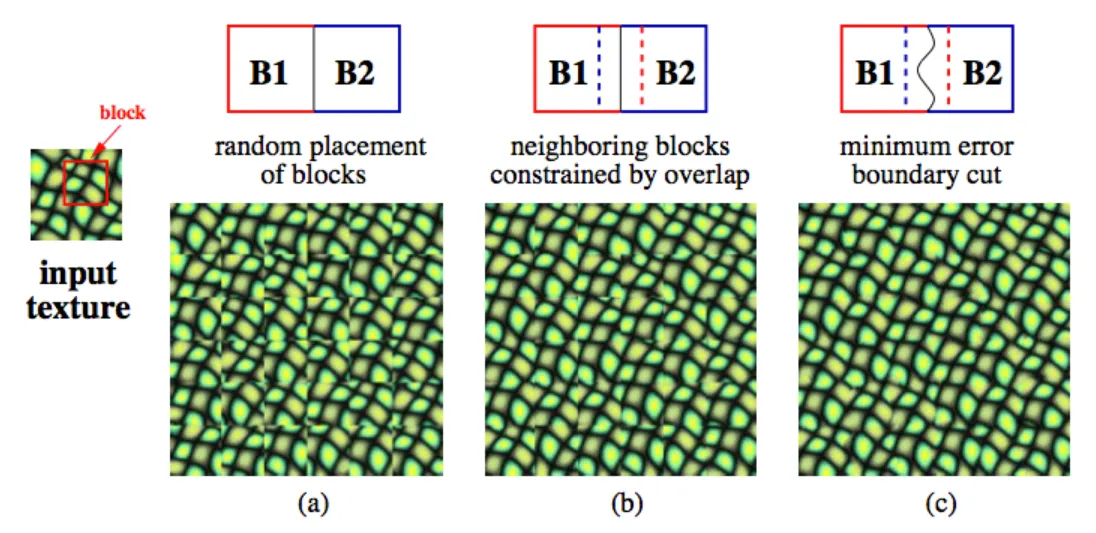
(a) represents taking some tile and randomly placing copies in a grid. As you can see, the edges of the textures are extremely obvious and the placement looks unnatural.
(b) represents taking that image texture, allowing it to overlap by some amount with its neighbors, and then choosing an arrangement of tiles that minimizes the summed difference in the overlapping regions. This ensures that tiles with similar edges are placed next to each other. As you can see, this is much smoother than the random assortment, but the grid-like edges are still visible if you’re looking for them.
© takes the same overlapping system from (b), but instead of a straight cut, it finds the lowest energy path for the boundary. In technical terms, this finds the 'minimum energy cut', meaning the path through the overlap where the pixels from both tiles are most similar. Consequently, the edges of each tile are no longer straight grid lines but are dynamically defined, making the transition visually smooth.
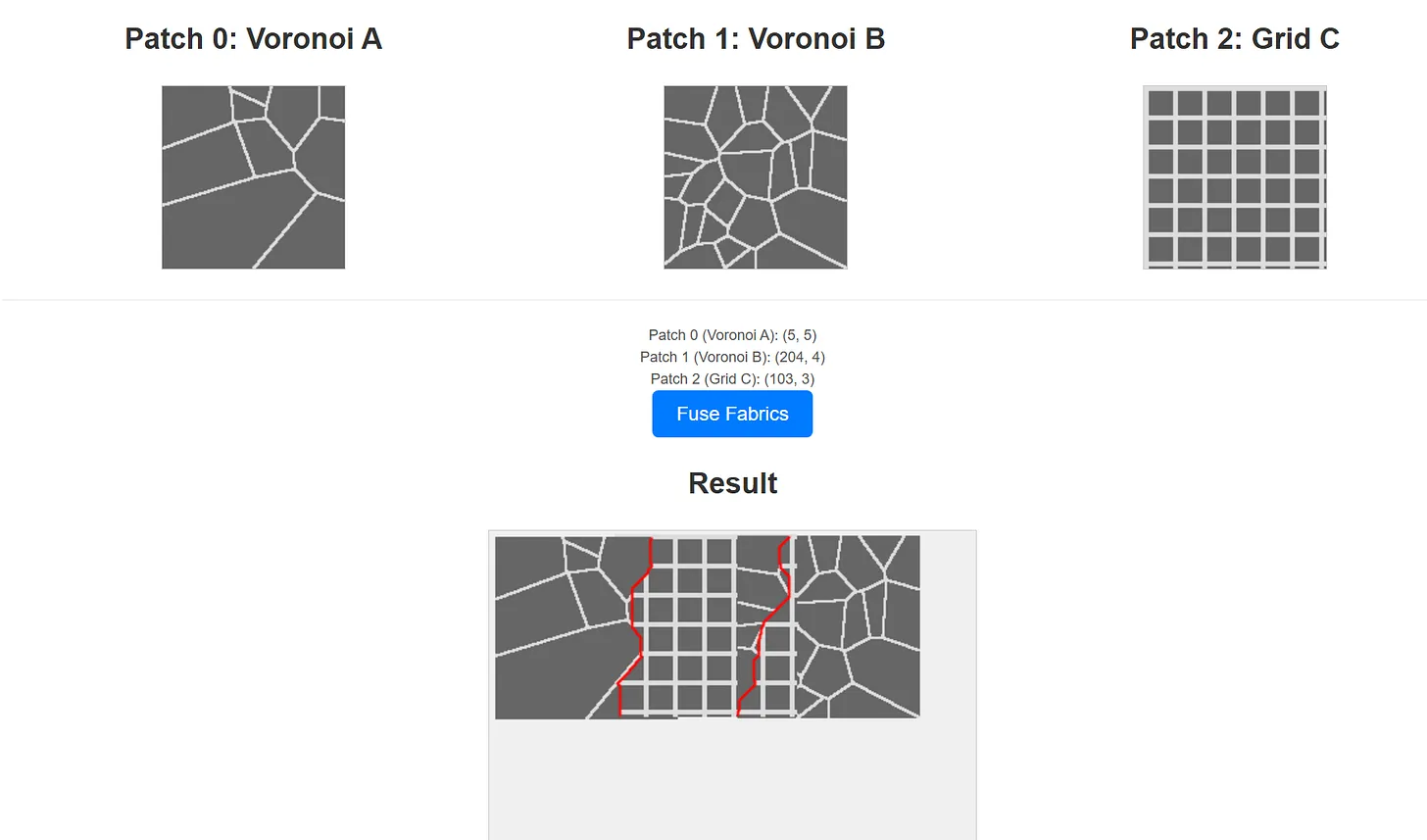
My thoughts about applications for this philosophy started with cities. I’ve often wanted to find a better way to smoothly transition between representations of two different cities, perhaps for generating fictional interstitial areas. I had previously experimented with representing city maps as graphs and finding shortest paths between nodes, but while that creates a connection, it isn't a realistic depiction of the infill between two potentially distinct urban environments. With image quilting logic, however, we could represent city features (like roads, buildings, parks) as different 'colors' or regions on a map and then 'quilt' them together.
I built a simplified version using basic procedural patterns (Voronoi and Grid) representing distinct city styles, treating 'Road' and 'Non-Road' areas essentially as two colors. While this simplified version primarily focused on finding good overlaps (akin to step B), a more rigorous approach would implement the minimum energy cut (step C) based on minimizing visual discontinuity across the boundary. The basic result (shown below) is promising, but likely needs a more nuanced method for defining the 'energy' cost (e.g., weighting the cost of cutting through buildings higher than cutting through parks in the energy minimization function, to encourage more plausible transitions).
But why stop here? As an abstracted core, this method is simply a philosophy of taking two different pieces and finding the smoothest way to connect them without introducing wholly new content. My next thought after cities was the usage of this in audio. If you can find the most similar parts between two audio tracks to cut between, you could potentially transition smoothly between them. The Eternal Jukebox is a fascinating related project, finding self-similar parts within a single song and randomly selecting different branches to jump between, allowing for a smooth listening experience that is theoretically infinite. An audio quilting technique, however, could allow for transitions between an arbitrary amount of different musical pieces, rather than just looping or rearranging one.
Think of it almost as an automatic DJ. Breaking down music into comparable components is harder than breaking down an image. Ideally, we would have the stems (the separated tracks like vocals, drums, bass) of all songs to transition smoothly, as the most suitable transition point for the vocal track might differ from the best point for the drum track. The technique would likely work better with a larger library of songs, as, similar to step B in image quilting, it could first find pairs of tracks with regions of high similarity before applying a low-energy splicing technique. Defining the 'minimum energy cut' for audio is more complex than for pixels; it might involve minimizing abrupt changes in waveform phase, spectral content, or perceived timbre across the transition point.
The final application I considered is Textual Quilting. I cannot for the life of me find the specific tweet, but it was essentially a joke riffing on the idea that “The next optimal page for you to read is rarely ever the next page in this book”. Textual quilting would take this to heart, attempting to find the next optimal, existing page (or paragraph, or sentence) from a corpus and appropriately stitching it together. My immediate thought was something like “Scaling this down to the optimal next sentence or next word seems like reinventing language models from first principles.”
This reflects the reality of the situation: for general purpose text generation, a textual quilting model would likely be less powerful than modern generative language models trained on vast datasets. However, one can imagine an alternate history or niche applications. Instead of being trained on the entire internet+, a model could take a defined subset of existing texts (say, several novels by one author, or a collection of philosophical works) and optimally stitch parts together. What would it maximize for? The fundamental challenge, as hinted before, is quantifying the 'difference' or 'energy' between semantic units (a much harder task than comparing pixel values or audio waveforms). While we would likely still need sophisticated semantic understanding reminiscent of modern language models to make this work well, there remains a sort of Borgesian fantasy in the idea of reading an optimally sequenced 'Ur-Book' stitched together from the finest passages of classic literature.